
A question I have been asked a number of times is how do we “Scale Agile”? There has been so much discussion of scaling frameworks such as LeSS, and SaFe, or Nexus or D.A.D. or even the Spotify model, that we have become conditioned to assume that these are the solution to any scaling or indeed any ‘Agile’ problem.
But as with so many situations and so many problems, deciding on a solution before fully considering the question at hand, leads to an outcome that is likely the wrong one and potentially unexpected and undesirable results.
What are you scaling?
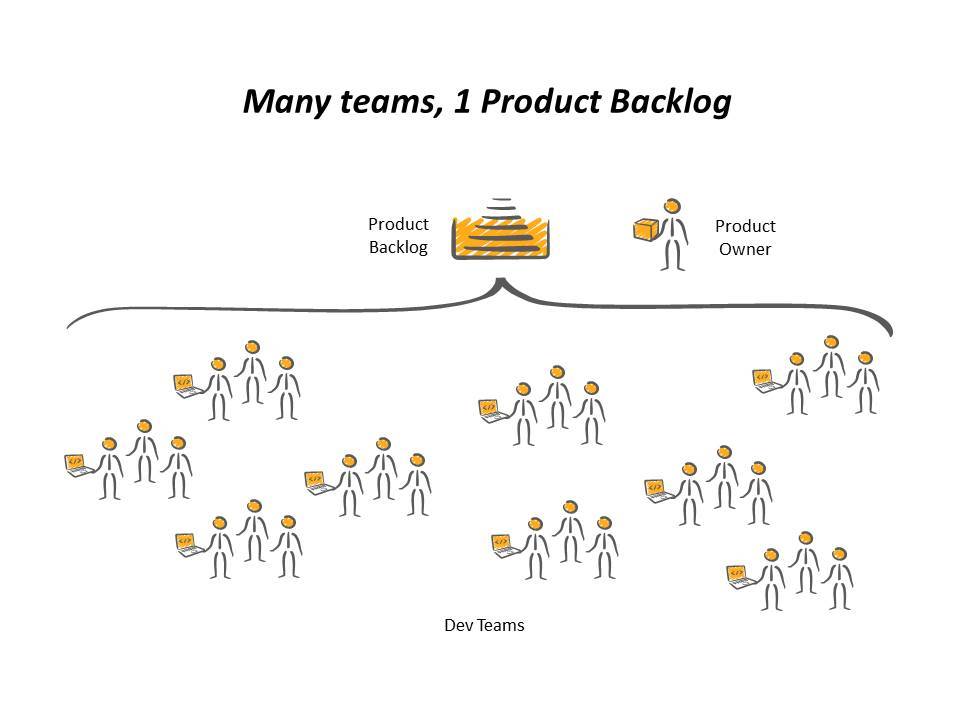
Most of the Scaling frameworks deal with organizing and communicating between multiple teams all of which are working on a single product. But that is not always the case, there is no ‘Normal’ and every organisation is different, some will have many teams and just one product, and some will have many teams and many products, and then there are the multitude of variations in between.
Many teams, Many products
But if the scaling agile frameworks cover the situation of many teams and one product what of the remaining situations? My instinctive response is to wonder whether this is actually an agile scaling question at all. It feels more a question of organisation scaling rather than agile scaling. That may feel like I am splitting hairs but I wonder if we are jumping to finding a solution to a problem that is neither new nor necessarily agile specific.
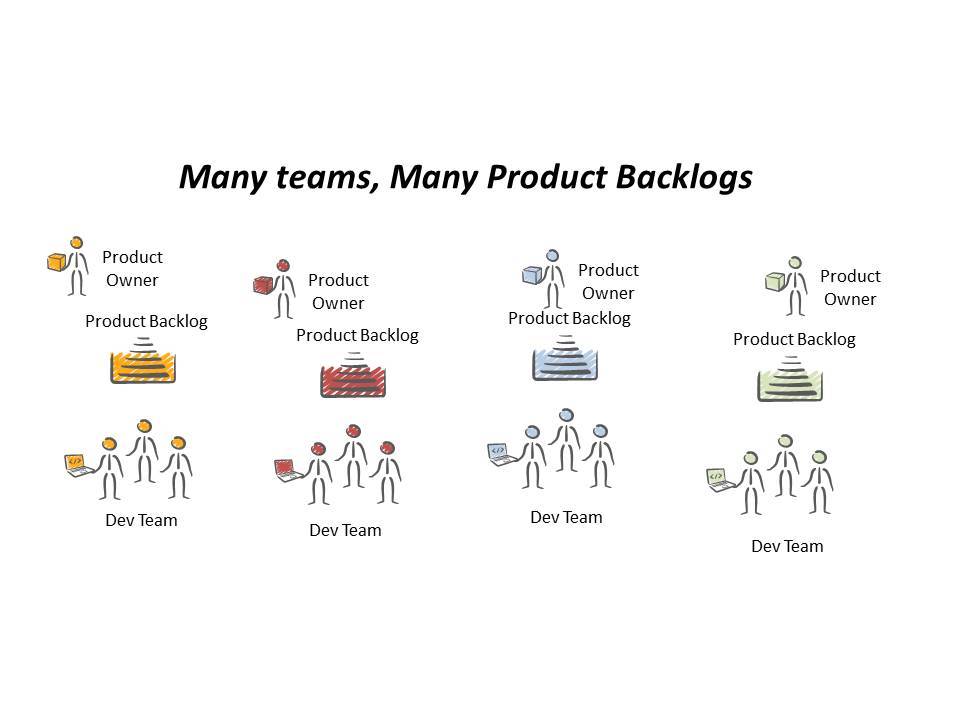
If our organisation is simply growing and we have more teams working on more products and there is little or no dependencies between the various teams then there is no scaling in the sense that these frameworks relate to. The agile frameworks provide a structure for shared communication and consistency of purpose, and there is an overhead for ensuring a common vision and a consistency of direction. All very important when there is strong dependencies and interactions between the teams.
But if you are able to organize your teams with autonomy of purpose, and are able to minimize the coupling and dependencies then are you really scaling or are you simply growing? The organisation that are multiple teams working on one product are genuinely candidates for scaling and so I will purposefully ignore them for the purposes of this post.
More teams does not mean you need a bureaucratic layer
The difference is that we don’t need huge amounts of overhead or a layer of bureaucracy, if we simply have a larger number of autonomous teams, then we are able to maintain a flat structure but simply grow and duplicate. Naturally there are elements of the organisation that will need to ‘scale’ to deal with the growing number of teams and people but this is not agile scaling of the teams themselves.
What about dependencies between teams
In some cases there will be teams that have dependencies on another team, but it may be possible to organize your products such that whilst dependencies occur, the dependent team becomes a (very important) stakeholder in the other product, and so there may be a case for prioritizing stories that support the dependency. However, there is not a tight coupling between these teams, they can still each be run almost entirely independently of each other.
Now this proposal is not entirely without overhead especially when there are teams that are inter-dependent. Identifying the boundaries between products may require some thought and effort. Coordinating the dependencies and ensuring they are given the appropriate priority will require some additional communication.
What about scaling on a small scale?
So that covers many teams and one product and many teams and many products, but what about a few teams and one product? This is actually the situation I consider most difficult.
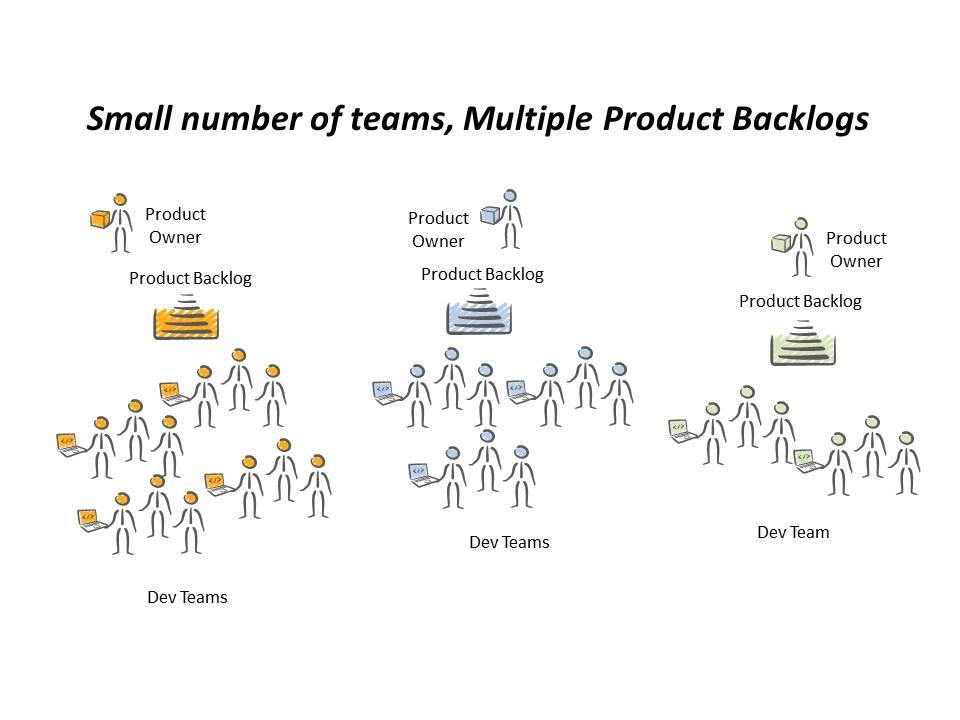
But these problems are likely not enough of a problem to warrant the large overhead of structure that a scaling framework imposes. Once again this seems to be more of a question of organisation than scaling, sure there is an element of scaling, but not so much that we need a heavyweight solution.
For this situation we may be able to make it work with something as simple as a few shared meetings (Scrum of Scrums) combined planning or refining session and a structured approach to delivery. Organisation, and dare I say it, the true sense of management - not throwing around orders, but coordinating, enabling communication, promoting transparency and creating a clear direction.
The Product Owner may also be able to think about stories in a context that works well with a multi team view. It may be that it is a single large product but could we divide by feature areas, or logical vertical slices of work. Yes there may be situations where there is overlap but it may be that we are able to write stories or share stories between the teams that intentionally minimize conflict. There are some elements that will require special consideration, such as UX which must be considered across the entire product and should be consistent, but that is not true for all stories.
But please do not underestimate the overhead of multiple teams - even just two, it is significant and can cripple the product delivery if not implemented well. You may need to lose some of the freedom of small teams, a shared definition of done, possible a common cadence, common deployment environments etc. And there is a greater need for trust in an environment that is less conducive to trust. It is not possible to be involved in all decisions in a multi team setup. There will be compromises and conflicts. So much so that in many situations you would be far better to consider extending the timescale and managing with one team.
Summary
- The first (many teams and 1 product) is well documented in the various Scaling Frameworks, I am not suggesting implementing them will be easy but they are well documented and there are many experts.
- The second - many teams, many products - is a question of organisation rather than scaling, so should be no harder than you have found it so far, it is repeating the same albeit with a few complications at an organisational level.
- But the last group fall in to a gap between the two extremes. If I have say two or three or even 4 or 5 teams working on one product, I will still have the usual communication difficulties, the need for consistency of direction becomes ever more important and we have a situation where teams can be highly dependent on each other.
It may sound like I am discouraging using the Scaled Frameworks, and I suppose in a sense I am, but not because I disagree with their use, but because they all carry with them quite significant overhead of effort and cost and in a lot of situations there is no benefit and may even be a severe detriment. If you can solve the problem with a little bit of organisation, rather than adding layers of overhead and bureaucracy, surely that is better?
Naturally every situation is different, consider each independently, but please don’t assume because you have multiple teams you need a scaling framework.
